Platte voll, ein Problem aus der Vergangenheit! Es gab Zeiten, in denen man seine Daten noch auf eigenen Maschinen hatte, und noch nicht alle Daten auf unlimitiertem Speicherplatz bei der NSA gelagert hat.
Aber vielleicht gibt es ja noch jemanden da draußen, der noch old-school Daten auf Platten abspeichert, und wissen will, wo denn jetzt die vielen TeraByte liegen.
Erster Anlaufpunkt ist immer “DiskFree”:
vecchio@NB-5753> df -h
Filesystem Size Used Avail Use% Mounted on
rootfs 475G 464G 12G 98% /
...Der Parameter “-h” führt dazu, dass die Größen “human-readable” angezeigt werden, also nicht immer in Bytes, sondern in sinnvollen Vielfachen davon. Sonst wäre das die Ausgabe:
Filesystem 1K-blocks Used Available Use% Mounted on
rootfs 497865724 486358960 11506764 98% /Ups, bei meinem Notebook ist die Platte recht voll. Aber wo muss ich denn jetzt suchen?
Die größten Verzeichnisse finden
Hier hilft “DiskUsage”. du zeigt alle Dateien im aktuellen Verzeichnis und seinen Unterverzeichnissen mit Größe an. Auch hier gibt es -h. Wenn ich das in meinem Home ausführe, dann ist die Ausgabe über 10000 Zeilen lang, das ist nicht hilfreich. Ich will ja erst mal die größten Verzeichnisse sehen. Dafür gibt es den Depth-Parameter, mit dem ich die Anzahl der auszugebenden Ebenen steuern kann:
vecchio@NB-5753> du -h -d1
235M ./.composer
0 ./.config
49M ./.electron
8.0K ./.gnupg
36M ./.local
0 ./.nano
2.8M ./.node-gyp
129M ./.npm
3.7M ./.oh-my-zsh
8.0K ./.ssh
32K ./.subversion
0 ./.vim
0 ./bin
454M .Offensichtlich sind in meinem Home hauptsächlich composer und npm groß, aber der Grund für die volle Platte liegt woanders. Das erste Problem sieht man aber hier schon gut: Die Ausgabe ist nach Verzeichnisnamen sortiert, und nicht nach Größe. Wenn man ein Verzeichnis mit hunderten Unterverzeichnissen und Files hat, dann wird es schwer zu finden wo die dicken Brocken sind.
Hier hilft sort weiter, das netterweise auch einen Parameter -h hat. Da sort standardmäßig aufsteigend sortiert brauchen wir auch noch den Reverse-Parameter:
vecchio@NB-5753> du -h -d1 | sort -rh
454M .
235M ./.composer
129M ./.npm
49M ./.electron
36M ./.local
3.7M ./.oh-my-zsh
2.8M ./.node-gyp
32K ./.subversion
8.0K ./.ssh
8.0K ./.gnupg
0 ./.vim
0 ./.nano
0 ./.config
0 ./binBei großen Verzeichnissen immer noch unpraktisch, also sollten wir uns auf die relevanten Verzeichnisse beschränken – wir zeigen einfach nur die obersten 5 Ergebnisse an:
vecchio@NB-5753> du -h -d1 | sort -rh | head -5
454M .
235M ./.composer
129M ./.npm
49M ./.electron
36M ./.localWas aber, wenn ich ein Verzeichnis habe, in dem tausende winzige Dateien liegen, und ich muss die wenigen Großen finden?
Große Dateien finden
du hilft hier nicht weiter, das geht nur auf Verzeichnisse, nicht auf Files. Aber find kann man gut benutzen, denn mittels des Parameters printf kann man dessen Ausgabe gut formatieren. Was zur Verfügung steht, kann man mit man find gut nachschauen, %s für die Dateigröße und %p für den Dateinamen (Warum auch immer das “p” ist…) sind hier das, was wir brauchen:
find . -type f -printf '%s %p\n' | sort -nr | head -20Also: Finde im aktuellen Verzeichnis “.” alle Dateien (Type f), und gib sie mit Größe und Dateinamen und abschließendem Zeilenumbruch (\n) aus. Sortiere das ganze numerisch und reverse, und gib anschließend nur die ersten 20 aus.
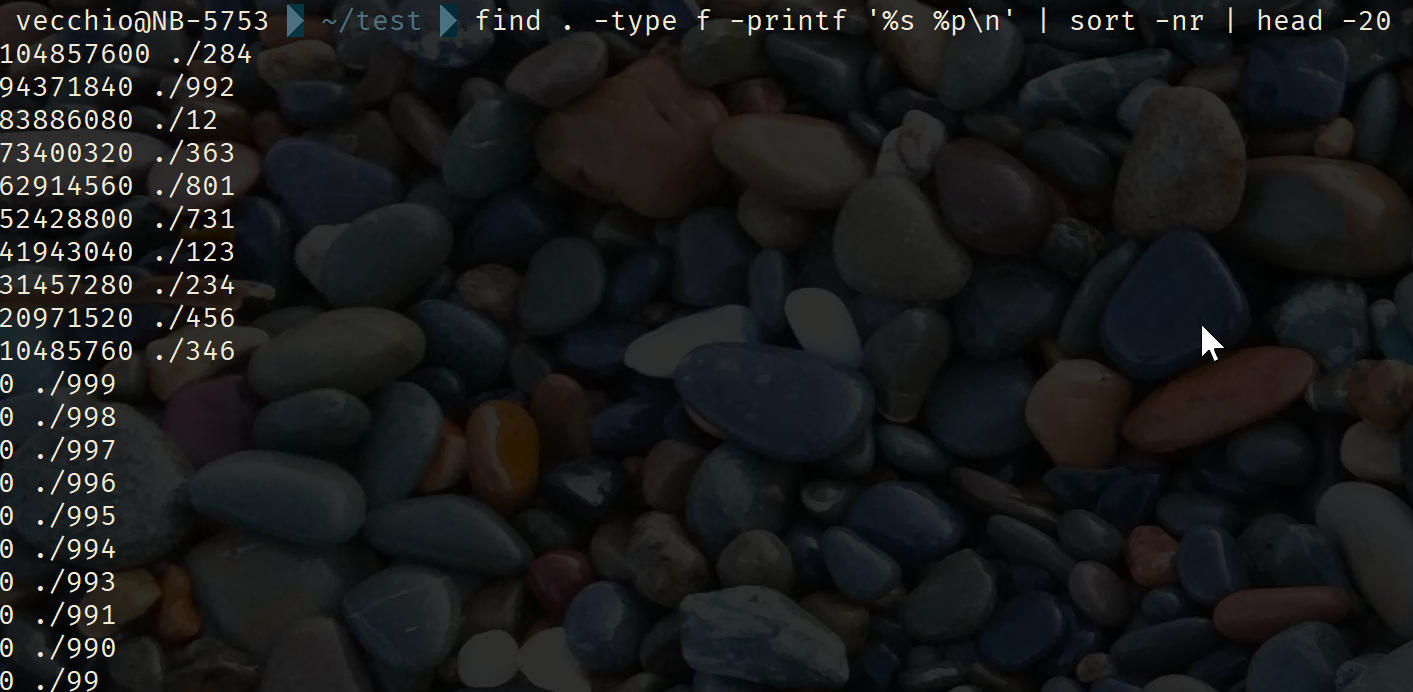
PS: Ich weiß, wo es bei meinem Notebook hakt: Bei virtuelle Maschinen kann man auch mal aufräumen. “Aber ich könnte die alte Debian-Box doch irgendwann noch mal brauchen! :-O”

Wenn man ” | numfmt –field=1 –to=iec-i” anhängt kriegt man die Dateigrößen in menschenlesbarer Form.